13/11/2013
New traffic record for GRNET NOC streaming service
Around a year ago I wrote a blog post about how me and @zmousm scaled our streaming infrastructure at GRNET NOC so that we could cope with a sudden demand on the streaming service that we provide to the Greek Parliament. That setup was re-used again in January 2013 (Lagarde-list discussion) where we managed to surpass our previous record of 1.66Gbps reaching 1.79Gbps. We knew that the previous solution could definitely be improved though. Wowza does not seem to scale very well in our environment(*cough* java *cough*), so we modified our setup quite a bit.
What we did was take the original Wowza streamer, and ‘hide’ it behind two different categories of ‘proxy-servers’ that clients communicate with. The first category is made of three varnish proxies sitting at two different datacenters. All clients that fetch HTTP streams communicate only with the varnish proxies and not with the original streamer. Varnish uses very few resources and scales wonderfully. Then we added an nginx-rtmp server to offload RTMP clients from the original streamer. Now all RTMP clients communicate with nginx-rtmp only. We’ve also notified website owners that prefer using our RTMP stream to serve it through their own (flash) applications to switch to the nginx-rtmp endpoint. This means that the original Wowza streamer now mainly serves the three varnish proxies and the nginx-rtmp server as ‘clients’, and since the VM now has far less load, the stream it provides to the ‘proxy-servers’ doesn’t get ‘chopped’ from time to time, as it did previously when it served hundreds of clients.
While each wowza streamer previously needed 6Gb of RAM to serve around 500-600Mbit of traffic, varnish needs <1Gb and can easily serve 900Mbit. Our nginx-rtmp server also uses <1Gb of RAM. So we’re actually using fewer resources to serve more (happier) clients!
This setup gives us a lot of flexibility and extensibility. We can easily scale it horizontally when we want to just by adding more varnish or nginx-rtmp servers.
With this setup we were able to achieve 3.55Gbps and serve more than 6000 clients last Sunday (10/11/2013), that’s double of our previous record!
Here are the graphs:
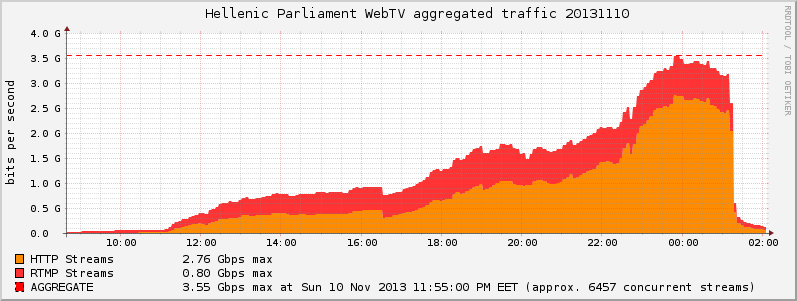
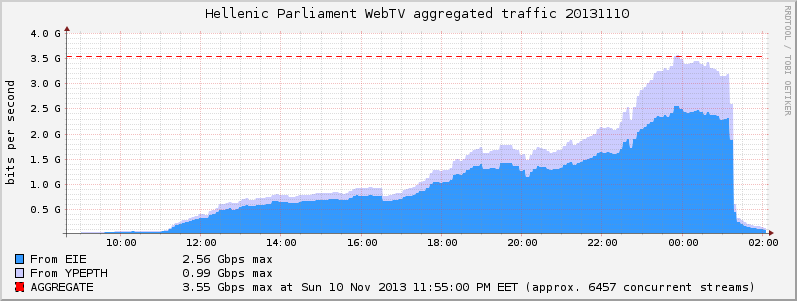
 Filed by kargig at 10:10 under Greek,Internet,Networking
Filed by kargig at 10:10 under Greek,Internet,Networking
Tags: Greek, grnet, HTTP, nginx, nginx-rtmp, parliament, rtmp, scaling, streaming, varnish, wowza
 12 Comments | 16,204 views
12 Comments | 16,204 views


